-> Hier kostenlos registrieren
Hallo zusammen,
ich verzweifle Momentan ein wenige an der folgenden Aufgabe. Verwendet wird dabei eine 1512SP und TIA V18.
Von einem Hersteller haben wir eine Protokollbeschreibung erhalten, welche wir nun in userer Steuerung umsetzen müssen. Das ganze basiert auf UDP. Die Pakete bestehen aus einem Header mit fester Größe, Nutzdaten mit variabler Größe und einem Trailer mit fester Größe (enthält CRC32 von Header und Nutzdaten).
Der Header besteht aus:
- einer ID (2 Byte)
- einer Sequenz (2 Byte)
- einem Telegramtyp (1 Byte)
- der Länge des Telegrams (2 Byte)
Der Telegramtyp beschreibt den zu erwarteten Inhalt der Nutzdaten. Die Größe der Nutzdaten kann hierbei auch bei dem gleichen Telegramtyp varieren.
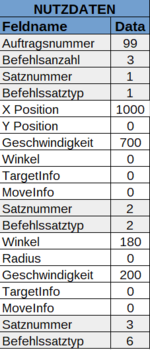
Ein Telegramtyp ist Bespielsweise "Befehl". Bei "Befehl" haben wir in den Nutzdaten des Telegrams:
- eine Auftragsnummer (UINT16)
- die Befehlsanzahl (UINT8)
- Befehlsnutzdaten (?Byte)
Die Befehlsnutzdaten bestehen wiederrum aus:
- Satznummer (UINT16)
- Befehlssatztyp (UINT8)
- Nutzdaten (?Byte, abhängig vom Befehlssatztyp)
Mein aktueller Stand ist, dass mit TCON die "Verbindung" aufgebaut wird und sobald das Fehlerfrei durch ist wird mit TURCV das Empfangen gestartet. Bei vollständigem Empfang werden die Daten in ein Array[0..2047] kopiert und die tatsächliche Anzahl der empfangenen Bytes gespeichert.
Folgenden Fragen ergeben sich bis jetzt:
- Ist die Herangehensweise soweit sinnvoll oder gibt es bereits hier einen besseren Weg?
- Wie wandle ich am besten meine Bytes aus dem Array in die entsprechenden Datentypen um? (z.B.: Array[12..13] -> Var_X:UINT)
- Wie gehe ich am besten durch mein Array um die Daten zu extrahieren und in entsprechende Strukturen zu schreiben? Viele verschachtelte CASE Anweisungen sind bis hier meine einzige Idee.
ich verzweifle Momentan ein wenige an der folgenden Aufgabe. Verwendet wird dabei eine 1512SP und TIA V18.
Von einem Hersteller haben wir eine Protokollbeschreibung erhalten, welche wir nun in userer Steuerung umsetzen müssen. Das ganze basiert auf UDP. Die Pakete bestehen aus einem Header mit fester Größe, Nutzdaten mit variabler Größe und einem Trailer mit fester Größe (enthält CRC32 von Header und Nutzdaten).
Der Header besteht aus:
- einer ID (2 Byte)
- einer Sequenz (2 Byte)
- einem Telegramtyp (1 Byte)
- der Länge des Telegrams (2 Byte)
Der Telegramtyp beschreibt den zu erwarteten Inhalt der Nutzdaten. Die Größe der Nutzdaten kann hierbei auch bei dem gleichen Telegramtyp varieren.
Ein Telegramtyp ist Bespielsweise "Befehl". Bei "Befehl" haben wir in den Nutzdaten des Telegrams:
- eine Auftragsnummer (UINT16)
- die Befehlsanzahl (UINT8)
- Befehlsnutzdaten (?Byte)
Die Befehlsnutzdaten bestehen wiederrum aus:
- Satznummer (UINT16)
- Befehlssatztyp (UINT8)
- Nutzdaten (?Byte, abhängig vom Befehlssatztyp)
Mein aktueller Stand ist, dass mit TCON die "Verbindung" aufgebaut wird und sobald das Fehlerfrei durch ist wird mit TURCV das Empfangen gestartet. Bei vollständigem Empfang werden die Daten in ein Array[0..2047] kopiert und die tatsächliche Anzahl der empfangenen Bytes gespeichert.
Folgenden Fragen ergeben sich bis jetzt:
- Ist die Herangehensweise soweit sinnvoll oder gibt es bereits hier einen besseren Weg?
- Wie wandle ich am besten meine Bytes aus dem Array in die entsprechenden Datentypen um? (z.B.: Array[12..13] -> Var_X:UINT)
- Wie gehe ich am besten durch mein Array um die Daten zu extrahieren und in entsprechende Strukturen zu schreiben? Viele verschachtelte CASE Anweisungen sind bis hier meine einzige Idee.